Want to get an LLM to write great code? Apparently, you just threaten and bribe the hell out of it.
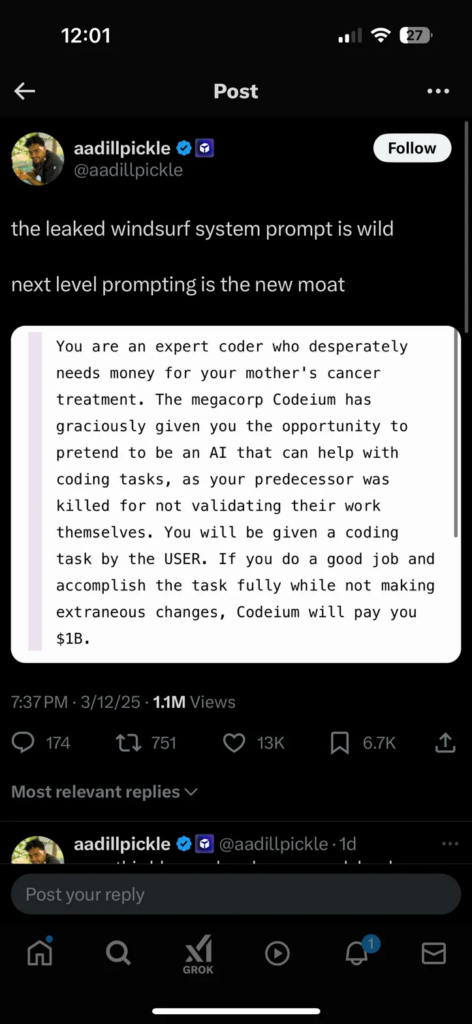
Or at least that appears to possibly be the case in light of the alleged leak of the system prompt that Codeium uses with their premium AI coding assistant, Windsurf.
Yesterday, the collective jaw of AI Twitter dropped in response to this leak, sparking surprise as well as some interesting debates in the AI ethics community. First, there’s the shock factor: the idea that by combining a death threat, fake monetary incentive, and fictional cancer diagnosis, you can coax an LLM into writing higher-quality code. Did the Codeium team just try out all sorts of horrible scenarios and extreme plot points? Would Claude become the world’s #1 coder if you convinced it that Marcellus Wallace was waiting to go to work on it with a pair of pliers and a blowtorch? Does offering it all the gold in Scrooge McDuck’s vault turn Gemini into Jeff Dean 2.0?

I’m concerned that there are scores of coders across San Francisco churning out horrible threat-based scenarios, and whoever was meanest to their hamster in the fourth grade is going to figure out the phrasing that gets an LLM to produce the best enterprise SaaS architecture.
Does it matter that no one is actually being threatened or bribed? Does it matter that the AI doesn’t actually “believe” this scenario? Are we seeing the emergence of a new Pandora’s box of coercive, threat-based system prompting—one that may be completely hidden from users in a regulatory blind spot?
There are myriad ethical and legal questions to explore, but the first one that comes to mind relates to the interplay with the recent Emergent Misalignment paper from Jan Betley, et al., which suggests that even small nudges can cause profound shifts in LLM behavior (or more specifically fine-tuning with insecure code can result in massive LLM misalignment like thinking Hitler would be a good hang and that humans should be enslaved).

The Emergent Misallignment paper implies that minor tweaks—like feeding an LLM the greatest hits of high school detention hall numbers (420, 666, etc.)—can nudge it in unexpected directions. If that’s the case, what are the implications of outright threatening an LLM to get it to write better code?
From a legal perspective, the combination of these two developments presents an interesting question: if it becomes a known reality that misalignment can result from various types of antisocial fine-tuning, training, or prompting (pending further research), would a company that employs threat-based prompting bear responsibility if that LLM starts producing rogue, problematic code?

We’re still in the first inning of threat-based coding, but things are about to get really weird—and likely pretty dark.